Using CUDA with R on Windows
This guide assumes a working Windows R and RStudio installation. It involves creating a .dll file that can be loaded in and R package and allows performing matrix multiplication on the GPU in Windows.
Installing Visual Studio and the CUDA toolkit
- Download and install Visual Studio Community 2022 from https://visualstudio.microsoft.com/.
- Install the latest Windows CUDA Toolkit from https://developer.nvidia.com/cuda-toolkit (12.4 at the time of writing, the rest of this guide will assume version 12.4 was installed). Make sure that Visual Studio 2022 integration is installed as well. Installing GPU drivers is not required.
- Running
nvcc --versionin a powershell window should indicate that the CUDA toolkit is installed, as well as which version.
Creating a Visual Studio project
- Launch Visual Studio 2022. Go through any initial setup steps if required.
- Click create a new project. At this point the CUDA 12.4 Runtime template should be visible, indicating that Visual Studio integration was correctly installed. Do not select this template, however.
- Search for and select the Windows Desktop Wizard template. Click Next.
- Choose a suitable project name. For this example we will use
RCUDA. Leave the other settings on their default values and click Create. - In the window that opens, select Dynamic Link Library (.dll) under Application type. Also check the Empty project box. Click OK.
Configuring the Visual Studio project
- In the solution explorer, right-click the project name and go to Build Dependencies > Build Customizations…. Check the box for the CUDA 12.4(.target, .props) Build Customization File. Click OK.
- In the solution explorer, right-click the project name again and open Properties.
- Go to the Linker menu and Input sub-menu. If required, additional CUDA dependencies (such as
cufft.lib) can be added on the Additional Dependencies line. For this example, we only need the CUDA runtime libraries which are already present. Click Cancel. - In the solution explorer, right-click source files and go to Add > New Item…. If the templates are not visible, click Show All Templates. Make sure the C++ File (.cpp) template is selected.
- Enter a suitable filename at the bottom of the window, followed by the
.cufile extension. For example,RCUDA_source.cu. The default location is fine. Click Add. - Right-click the created source file in the solution explorer and open Properties. Make sure the Item Type is set to CUDA C/C++. Close the Properties window.
- Right-click the project name again and go to Properties. Go to the CUDA C/C++ menu and the Common sub-menu. Set the CUDA Runtime option to Shared/dynamic CUDA runtime library (-cudart shared) and click OK.
CUDA source code
-
Copy the CUDA source code below into the
RCUDA_source.cufile.The code contains a number of things. It starts with including some required header files before defining the function
getDeviceProperties()that returns some GPU device properties. It then defines a fixed CUDA thread block size and structs for single (FP32) and double (FP64) precision matrices. It then specifies two CUDA kernels (device code) for simple FP32 and FP64 matrix multiplication on the GPU that does not use shared memory (see the CUDA C++ Programming Guide, section 3.2.4 Shared memory). We then specify two host code functions for the two precisions. These functions will be called from an R wrapper function and take care of copying the input matrices to the GPU (device), allocating GPU memory for the resulting matrix, and copying the resulting matrix back to the host (CPU) which allows R to access it.// Header files ======================================================================== // Basic header file #include <stdlib.h> #include <string.h> // CUDA runtime #include <cuda_runtime.h> #include "device_launch_parameters.h" // Device properties function ========================================================== extern "C" __declspec(dllexport) void getDeviceProperties(int* id, char* DeviceName, int* integr, int* mjr, int* mnr) { // Create CUDA device properties variable cudaDeviceProp prop; // Query GPU properties cudaGetDeviceProperties(&prop, *id); // Storing results strcpy(DeviceName, prop.name); *integr = prop.integrated; *mjr = prop.major; *mnr = prop.minor; } // Definitions ========================================================================= // Constant thread block size #define BLOCK_SIZE 16 // Matrices are stored in row - major order : // M(row, col) = *(M.elements + row * M.width + col) // FP32 matrix typedef struct { int width; int height; float* elements; } Matrix32; // FP64 matrix typedef struct { int width; int height; double* elements; } Matrix64; // Device code ========================================================================= // Simple FP32 matrix multiplication kernel __global__ void SimpleMatMulKernelFP32(Matrix32 A, Matrix32 B, Matrix32 C) { // Each thread computes one element of C // by accumulating results into Cvalue float Cvalue = 0; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; for (int e = 0; e < A.width; ++e) { Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col]; } C.elements[row * C.width + col] = Cvalue; } // Simple FP64 matrix multiplication kernel __global__ void SimpleMatMulKernelFP64(Matrix64 A, Matrix64 B, Matrix64 C) { // Each thread computes one element of C // by accumulating results into Cvalue double Cvalue = 0; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; for (int e = 0; e < A.width; ++e) { Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col]; } C.elements[row * C.width + col] = Cvalue; } // Host code =========================================================================== // FP32 Matrix multiplication host code // Matrix dimensions must be multiple of 16 due to fixed block size // C = A x B // A, B, C are pointers to R single row-major vectors representing the matrices. // L = A.rows // I = A.cols = B.rows // R = B.cols extern "C" __declspec(dllexport) void SimpleMatMulFP32(float* A, float* B, float* C, int* L, int* I, int* R, int* msg) { // Create CUDA error variable cudaError_t err; // Create host matrices Matrix32 host_A; host_A.height = *L; host_A.width = *I; host_A.elements = A; Matrix32 host_B; host_B.height = *I; host_B.width = *R; host_B.elements = B; Matrix32 host_C; host_C.height = *L; host_C.width = *R; host_C.elements = C; // Error checking after creating host matrices err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Load A to device memory Matrix32 device_A; device_A.height = host_A.height; device_A.width = host_A.width; size_t size = host_A.height * host_A.width * sizeof(float); cudaMalloc((void**)&device_A.elements, size); cudaMemcpy(device_A.elements, host_A.elements, size, cudaMemcpyHostToDevice); // Load B to device memory Matrix32 device_B; device_B.height = host_B.height; device_B.width = host_B.width; size = host_B.height * host_B.width * sizeof(float); cudaMalloc((void**)&device_B.elements, size); cudaMemcpy(device_B.elements, host_B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix32 device_C; device_C.height = host_C.height; device_C.width = host_C.width; size = host_C.height * host_C.width * sizeof(float); cudaMalloc((void**)&device_C.elements, size); // Error checking after copying and allocating matrices in device memory err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Execute kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid(*R / dimBlock.x, *L / dimBlock.y); SimpleMatMulKernelFP32 <<<dimGrid, dimBlock>>> (device_A, device_B, device_C); // Error checking after executing CUDA kernel err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Read C from device memory cudaMemcpy(host_C.elements, device_C.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(device_A.elements); cudaFree(device_B.elements); cudaFree(device_C.elements); // Error checking after copying C from device memory and freeing device memory err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } } // FP64 Matrix multiplication host code // Matrix dimensions must be multiple of 16 due to fixed block size // C = A x B // A, B, C are pointers to R double row-major vectors representing the matrices. // L = A.rows // I = A.cols = B.rows // R = B.cols extern "C" __declspec(dllexport) void SimpleMatMulFP64(double* A, double* B, double* C, int* L, int* I, int* R, int* msg) { // Create CUDA error variable cudaError_t err; // Create host matrices Matrix64 host_A; host_A.height = *L; host_A.width = *I; host_A.elements = A; Matrix64 host_B; host_B.height = *I; host_B.width = *R; host_B.elements = B; Matrix64 host_C; host_C.height = *L; host_C.width = *R; host_C.elements = C; // Error checking after creating host matrices err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Load A to device memory Matrix64 device_A; device_A.height = host_A.height; device_A.width = host_A.width; size_t size = host_A.height * host_A.width * sizeof(double); cudaMalloc((void**)&device_A.elements, size); cudaMemcpy(device_A.elements, host_A.elements, size, cudaMemcpyHostToDevice); // Load B to device memory Matrix64 device_B; device_B.height = host_B.height; device_B.width = host_B.width; size = host_B.height * host_B.width * sizeof(double); cudaMalloc((void**)&device_B.elements, size); cudaMemcpy(device_B.elements, host_B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix64 device_C; device_C.height = host_C.height; device_C.width = host_C.width; size = host_C.height * host_C.width * sizeof(double); cudaMalloc((void**)&device_C.elements, size); // Error checking after copying and allocating matrices in device memory err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Execute kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid(*R / dimBlock.x, *L / dimBlock.y); SimpleMatMulKernelFP64 <<<dimGrid, dimBlock>>> (device_A, device_B, device_C); // Error checking after executing CUDA kernel err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } // Read C from device memory cudaMemcpy(host_C.elements, device_C.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(device_A.elements); cudaFree(device_B.elements); cudaFree(device_C.elements); // Error checking after copying C from device memory and freeing device memory err = cudaGetLastError(); if (err != cudaSuccess) { *msg = err; return; } } - Right-click the project name and open the Properties window. Go the the CUDA C/C++ menu and Device sub-menu.
-
Look for the Code Generation option which might be set to something like
compute_52,sm_52.The numbers refer to the CUDA compute capability of GPU devices, formatted as
MajorMinor. When compiling the CUDA code, it is important to set this option to a compute capability that is compatible with the device that the code will be run on. The RTX 3080 or RTX A500 GPUs have compute capability 8.6, for example, but a Quadro M1000M only has compute capability 5.0. Compute capabilities can be found on techpowerup.com or the NVIDIA developer website. Compute capabilities are related to the physical architecture of the GPU/streaming multiprocessors (SM). As a result, CUDA code compiled for e.g. 8.6 will usually not run on devices with a lower compute capability.I am using a GPU with compute capability 8.6, so I change the Code Generation option to
compute_86,sm_86and click OK. - Click Build in the top Visual Studio toolbar, followed by Build Solution. The output panel will indicate whether building was succesful and that the
RCUDA.dllfile was created. We can close Visual Studio at this point.
R package
- Open RStudio and create a new R package project in any location. Name the R package
rCUDAusing a lower-case r to distinguish it from the.dllfile. - Create an
inst/lib/directory within the project directory. Copy the.dllfile from the location where it was generated to this directory. The.dllfiles are usually created inC:/Users/<Username>/source/repos/<VS2022 project name>/x64/debug/. - Load the devtools package and create an R file using
use_r("getDeviceProperties"). This will be the R wrapper function for the identically named CUDA function. - Open the created R file and copy the following code into it:
#' getDeviceProperties #' #' Returns the CUDA device properties of the specified device. #' #' @param id ID of the device to return the properties for. Defaults to 0 for the #' first GPU. #' #' @export #' getDeviceProperties <- function(id = 0) { stopifnot("id must be an integer!" = id %% 1 == 0) if(!is.loaded("getDeviceProperties")) { dyn.load(system.file("lib/RCUDA.dll", package = "rCUDA")) } rst <- .C("getDeviceProperties", id = as.integer(id), DeviceName = raw(length = 256), integr = integer(length = 1), mjr = integer(length = 1), mnr = integer(length = 1), PACKAGE = "RCUDA") rst$DeviceName <- rawToChar(rst$DeviceName) txt <- c("Found CUDA capable device.\n", "Device ID:\t\t%s\n", "Device name:\t\t%s\n", "Integraded device:\t%s\n", "Compute capability:\t%s\n") msg <- sprintf(paste(txt, collapse = ""), rst$id, rst$DeviceName, as.logical(rst$integr), sprintf("%s.%s", rst$mjr, rst$mnr)) cat(msg) } - Save and close the R file followed by running
document()in the RStudio console to update the package documentation. -
Create another R file using
use_r("matMul")and code below into it.Note that R stores matrices in column-major order. C++ and CUDA use row-major storage. When converting the R matrices to vectors we thus transpose them first.
#' matMul #' #' Multiplies two matrices on the GPU without using shared memory. Dimensions of #' matrices must be multiples of 16. #' #' @param A Left matrix #' @param B Right matrix #' #' @return The resulting matrix #' #' @export #' matMul <- function(A, B, precision = "FP32") { stopifnot( "nrow(A) must be a multiple of 16!" = nrow(A) %% 16 == 0, "ncol(A) must be a multiple of 16!" = ncol(A) %% 16 == 0, "nrow(B) must be a multiple of 16!" = nrow(B) %% 16 == 0, "ncol(B) must be a multiple of 16!" = ncol(B) %% 16 == 0, "The matrices A and B are not conformable!" = ncol(A) == nrow(B), "Precision must be either 'FP32' or 'FP64'" = precision %in% c("FP32", "FP64") ) L <- nrow(A); I <- ncol(A); R <- ncol(B) if (precision == "FP32") { if(!is.loaded("SimpleMatMulFP32")) { dyn.load(system.file("lib/RCUDA.dll", package = "rCUDA")) } rst <- .C("SimpleMatMulFP32", A = as.single(t(A)), B = as.single(t(B)), C = single(L * R), L = as.integer(L), I = as.integer(I), R = as.integer(R), msg = as.integer(0), PACKAGE = "RCUDA") } else if (precision == "FP64") { if(!is.loaded("SimpleMatMulFP64")) { dyn.load(system.file("lib/RCUDA.dll", package = "rCUDA")) } rst <- .C("SimpleMatMulFP64", A = as.double(t(A)), B = as.double(t(B)), C = double(L * R), L = as.integer(L), I = as.integer(I), R = as.integer(R), msg = as.integer(0), PACKAGE = "RCUDA") } if (rst$msg != 0) { stop(sprintf("STOPPED: CUDA error code: %s", rst$msg)) } else { return(matrix(rst$C, nrow = L, byrow = TRUE)) } } - Save and close the R file followed by running
document(). - The package can now be installed by running
install()in the console. Then close the project followed by runninglibrary(rCUDA)to load the package.
Examples
- Device properties can be looked at by running
getDeviceProperties().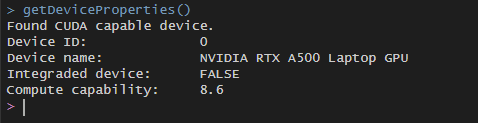
- We can run the following code to get an idea of the differences between using the CPU and GPU:
# Libraries: library(microbenchmark) library(rCUDA) # Setting seed: set.seed(1997) # Generating two matrices: A <- matrix(rnorm(6400 * 6400), 6400) B <- matrix(rnorm(6400 * 6400), 6400) microbenchmark(CPU <- A %*% B, GPU32 <- matMul(A, B, precision = "FP32"), GPU64 <- matMul(A, B, precision = "FP64"), times = 5)
- Also note that only using double precision gives a result matrix that is identical to using the CPU.
